
Парсинг сайтов с помощью DataCol
Обзор программы DataCol, предназначенной для парсинга сайтов на примере сбора базы данных отелей с сайта booking.com.

Для наполнения своего сайта контентом часто возникает необходимость собрать информацию с какого-то чужого ресурса, чтобы затем использовать ее в своем проекте. Например, для туристических сайтов нужны базы отелей, для магазинов – базы товаров и т.д.
Процесс автоматического вычленения нужной информации с сайта называется парсингом. Часто подобную задачу решают с помощью программиста, но сегодня я расскажу о программе Datacol, которая позволяет парсить многие сайты без умения программировать.
Сразу хочу сказать, что программа Datacol обладает хорошими возможностями для парсинга сайтов, но имеет очень запутанный интерфейс. Поэтому данный обзор я решил сделать в виде небольшого туторила, в котором будет показано, как настроить парсинг на реальном примере.
Скачать демо версию Datacol можно с сайта разработчика. Единственное отличие демо версии от полнофункциональной заключается в невозможности экспорта данных. Так что перед покупкой стоит обязательно попробовать парсер в работе на нужных вам сайтах.
Итак, программа скачана и установлена, запустим ее.
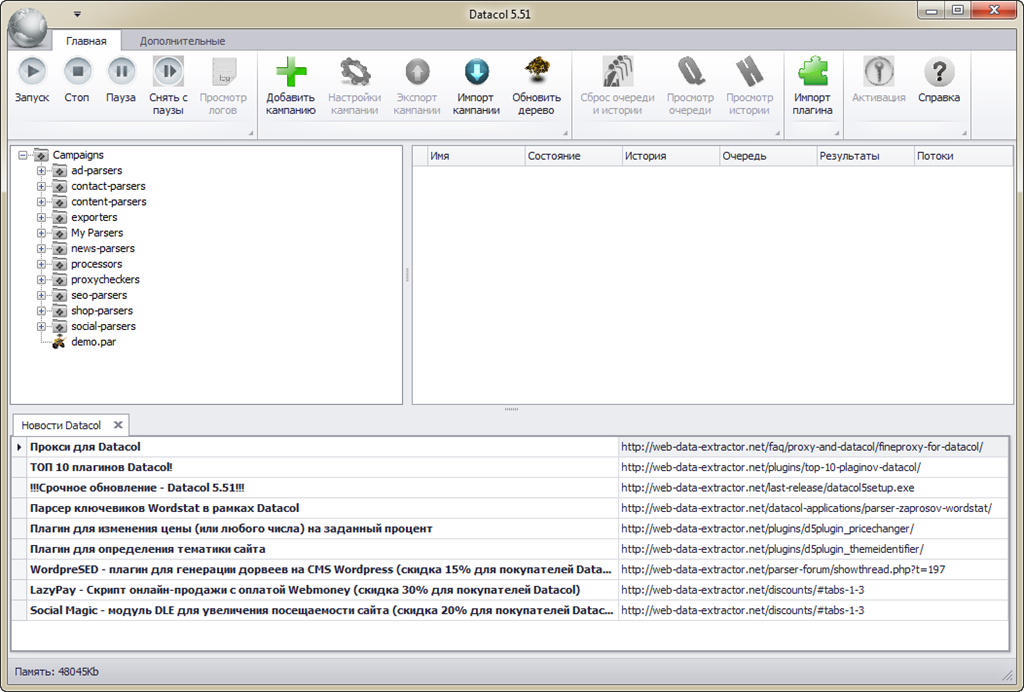
Вид главного окна после первого запуска вызвал у меня шок непонимания.
Очевидно, что в верхней части окна находится тулбар. Но что произойдет, если нажать первую кнопку “Запуск”?
Чуть ниже расположен древовидный список каких-то кампаний, а справа от него пустой грид.
В нижней части находится список новостей от Datacol. Двойной клик на новости откроет соответствующую страницу в браузере. Только зачем нужен полный урл новости справа?
К счастью для меня на главной страницу сайта программы есть видео из которого можно получить основные сведения по работе с программой. Рекомендую с ним сразу ознакомиться:
В общем, становится понятно, что кампании – это настройки парсинга определенного сайта. Разработчики включили в комплект программы пару десятков готовых кампаний для парсинга популярных сайтов.
Пример парсинга сайта
Создание кампании парсинга
Я создам новую кампанию для парсинга отелей с сайта booking.com. Для этого надо нажать кнопку “Добавить кампанию”, ввести название кампании (советую называть по имени сайта) в появившемся диалоге и выбрать тип кампании “парсер”.
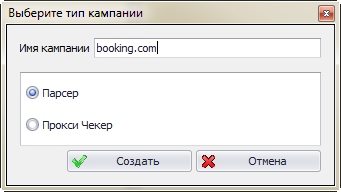
После нажатия кнопки создать, откроется окно настройки кампании:
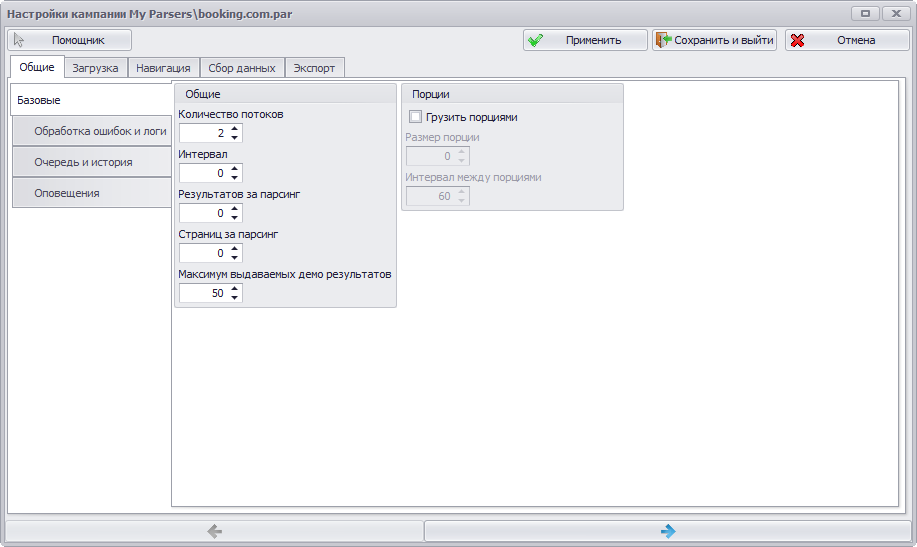
Основные настройки
Я не буду подробно описывать все настройки приложения – для этого есть документация. Отмечу только, что есть возможность достаточно гибко настроить парсинг: можно собирать данные сразу в несколько потоков, а можно делать это осторожно, делая паузы между страницами, чтобы минимизировать вероятность бана.
На вкладке “Загрузка” можно выбрать кэширование страниц:

Это позволяет не тратить время на повторное обращение к сайту, что очень удобно в процессе настройки и тестирования парсинга. Когда кампания будет полностью настроена и вы начнете сбор данных, отключите кэширование.
Если сайт борется с автоматическим сбором данных, вам пригодится возможность задания списка проксей, через которые будет происходить загрузка страниц. Причем Datacol умеет проверять их работоспособность (помните тип кампании “Прокси чекер” в диалоге создании новой кампании?).
На некоторых сайтах нужная информация может быть доступна только зарегистрированным пользователям. Для этого имеется раздел “Авторизация”.
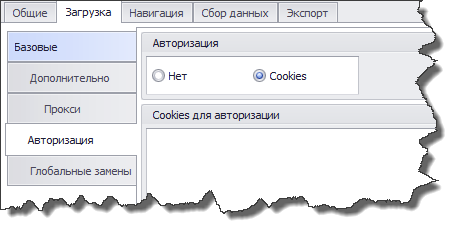
Работает авторизация довольно странным способом: вам надо войти на сайт в браузере, после чего скопировать авторизационные куки в текстовое поле. Разобраться как и что копировать неподготовленному пользователю будет непросто. Непонятно, почему разработчики не могли сделать автоматический импорт кук из браузера или возможность логина на сайт через окно приложения.
Обход страниц сайта
Перейдем теперь к непосредственно парсингу, который состоит из двух шагов: получение страниц с нужными нам данными и непосредственно парсинг интересующих нас данных со страниц сайта.
Первый шаг настраивается с помощью закладки “Навигация”.

Для начала работы необходимо указать как минимум один урл, с которого начнется загрузка страниц сайта. Для данного примера я открыл в браузере сайт booking.com и выбрал список отелей Киева.

Получившийся урл скопировал в поле “Список начальных URL”.
Очевидно, что этот список содержит ссылки на страницы, с которых нам надо собрать информацию про отели (название, описание, фотографии и т.п.). Кроме того, в нижней части находится навигатор по страницам списка, так как все отели не влезли на одну страницу.
Чтобы загрузить все части списка отелей, а также страницы с отелями, используем раздел “Сбор ссылок” закладки “Навигация”.

Здесь надо указать, какие ссылки (url) использовать для загрузки полного списка отелей и страниц самих отелей. Сделать это можно двумя способами: с помощью XPath и с помощью регулярных выражений. Оба эти инструмента не просты для понимания и требуют тщательного изучения для осмысленного применения.
К счастью, разработчики Datacol сделали специальный помощник, который умеет составлять XPath запросы и регулярные выражения вместо вас.

Чтобы им воспользоваться, нажимаем одноименную кнопку. В открывшееся окно вставляем урл первой страницы со списком отелей и нажимаем кнопку “Переход”. В правой части окна откроется нужная нам страница, а в левой будет показан ее html код.

Чтобы передать помощнику информацию о ссылках на страницы с описанием отеля достаточно кликнуть правой кнопкой мыши по ссылке на отель. После этого появится диалоговое окно с подобранным XPath выражением. В правой части этого окна отображается соответствующая часть html кода страницы.
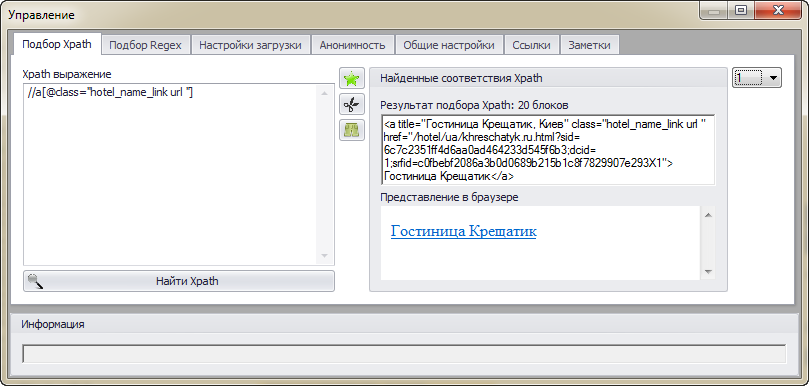
Обратите внимание на выпадающий список справа, содержащий цифры от 1 до 20. Через него можно выбрать другие части html кода страницы, соответствующие XPath выражению. В данном случае таких частей 20, как и отелей на странице. Т.е. Datacol сможет получить все 20 ссылок на описания отелей.
Теперь прокручиваем страницу вниз до постраничной навигации. Надо указать ссылки, по которым парсер сможет пройти по другим страницам списка отелей. Для этого можно кликнуть правой кнопкой мыши по ссылке “Следующая страница”. В результате помощник подберет для этой ссылки XPath выражение:
//a[@class="paging-next ga\_sr\_gotopage\_2\_21"]
Человеческим языком это означает: найти html тег <a> с атрибутом class равным “paging-next ga_sr_gotopage_2_21”. К сожалению, на второй странице ссылка для перехода к следующей странице выводится уже не с классом ga_sr_gotopage_2_21, а с классом ga_sr_gotopage_3_21 и наше XPath выражение не сможет его выбрать.
Придется воспользоваться головой и написать свой вариант:
//a[contains(@class,"paging-next")]Это выражение будет получать ссылку “Следующая страница” правильно.
Сбор данных
Перейдем теперь непосредственно к парсингу информации об отелях. Для этого открываем вкладку “Сбор данных”.

Пользовательский интерфейс становится еще сложнее. К двум рядам табов добавился еще один. По сути, перед вами трехмерный пользовательский интерфейс.
Ладно, если один раз разобраться, то в дальнейшем особых сложностей с управлением не возникает. Слева сразу выбираем “Поля данных”. Для простоты будем парсить только 4 поля: Название и описание отеля и фотографии (полноразмерные и превью).
Нажимаем кнопку “Добавить” и вводим название поля, которое будет содержать название отеля (я назвал его HotelName). После этого открываем помощник, указываем урл с описанием отеля (любого) и кликаем на названии правой кнопкой мыши.
Теперь аналогично добавляем поле для описания отеля. С помощью помощника получим такое XPath выражение:
//div[@id="summary"]/pК сожалению, с его помощью парсится только первый абзац описания. Чтобы получить полное описание меняем тип поля на “статическое” и выбираем “Сохранять теги” (не обязательно, но пригодится для сохранения разбивки по абзацам).

Теперь надо переключиться на вкладку “Статические” и убрать запятую из поля “Строка объединения”.
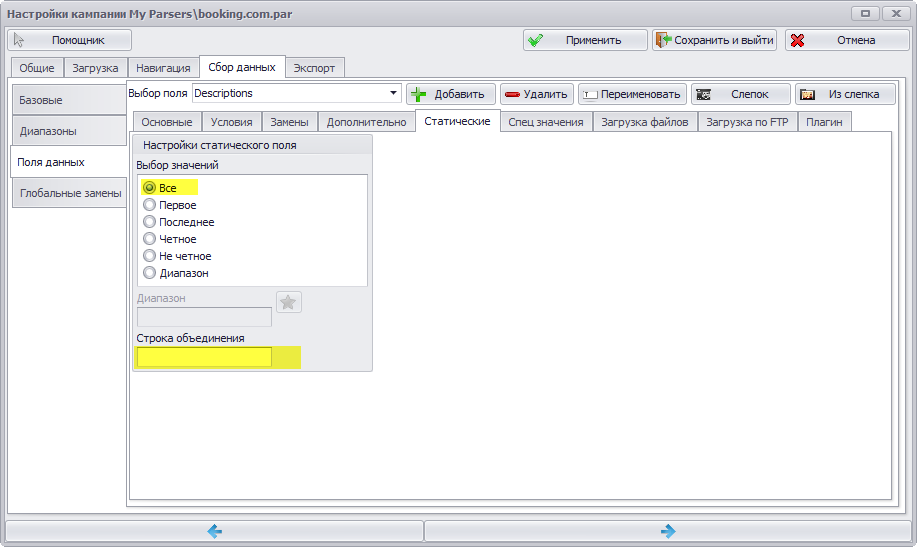
Этими настройками мы указываем программе собрать все подходящие куски html кода. В данном случае это все абзацы описания отеля.
Теперь создадим поля полноформатных и превью фотографий отеля (ImageLarge и ImageSmall). С помощью помощника получим такое XPath выражение:
//a[@class="change\_large\_image\_on\_hover hotel\_thumbs\_sprite"]
С помощью этого XPath вырезается кусок html, показанный в правой части окна помощника. Желтым я выделил те части, которые содержат нужные ссылки на фотографии (определил опытным путем). Мы их получим чуть позже, а сейчас копируем XPath в поле “XPATH вырезания” для обоих полей, выставляем тип поля в “Статическое” и выбираем “Сохранять теги”.

На вкладке “Статические” можно оставить запятую или использовать другой символ-разделитель.
Datacol умеет не только получать ссылки на изображения, но и скачивать их на компьютер (и даже заливать на ваш ftp сервер). Для этого служит закладка “Загрузка файлов”. Кроме того, этот же функционал поможет нам выделить “чистые” урлы фотографий.

Итак, отмечаем “Загружать файлы”.
Папку для сохранения можно выбрать любую на вашем компьютере.
Виртуальный путь – это тот путь, где будут лежать файлы на вашем сайте. Вместе с настройкой “Возвращать виртуальные пути” этот параметр влияет на конечный урл изображения. Я установил значение “/”, т.е. папка с изображениями будет находиться в корне сайта.
Настройка “Оставлять существующие” означает, что если файл уже скачан, то загрузка повторяться не будет (удобно при тестировании кампании).
Генерация подпапок будет происходить по заданной формуле, где %HotelName% – поле “Название отеля”. Т.е. фотографии отелей будут разложены по соответствующим папкам.
Наконец, в последнее поле, “Правила идентификации ссылки”, запишем следующее регулярное выражение:
data-resized="([^"]\*?)"Оно будет применено к куску html кода, вырезаемом XPath выражением выше и означает, что надо вернуть текст в кавычках после “data-resized=”, т.е. путь к полноразмерной фотографии.
Уменьшенные (превью) фотографии отелей получаются точно так же, меняется только регулярное выражение для ссылки и формула.

Все! Парсинг отелей настроен! Можно сохранять кампанию и запускать процесс.
Конечно, для сбора полноценной базы отелей надо будет добавить еще и другие поля, но основной принцип, надеюсь, ясен.
Получилось довольно сложно. Еще сложнее было разобраться с этими настройками. Воспользоваться логикой не получится и единственный способ разобраться с программой – внимательно прочитать всю справку (я именно так и сделал).
Дополнительно
Расширение функциональности с помощью плагинов
В описанном примере парсинга я показал лишь часть возможностей программы. Но даже полный набор возможностей не гарантирует, что вы не столкнетесь с нерешаемой задачей парсинга средствами Datacol. Для этого случая имеется система плагинов, с помощью которых можно расширять функциональность программы.
Планировщик
С помощью встроенного планировщика можно гибко настроить автоматический запуск созданных кампаний в заданное время.
Загрузка файлов по ftp
Я показал, как настроить скачивание фотографий с сайта-донора. Дополнительно можно автоматически загружать скачанные файлы на ваш сайт через ftp.
Экспорт
Результаты парсинга можно экспортировать в несколько форматов: текст, Excel, MySql, Wordpress. С помощью плагинов можно добавлять другие форматы экспорта.
Форум
На сайте разработчика есть форум на котором можно попробовать что-то спросить, но помогать бесплатно там не любят.

С одной стороны я понимаю разработчиков: если всем помогать с настройками, то не будет времени на добавление новых фич. Но с другой стороны отношение к людям, купившим программу, слишком наплевательское.
Кстати, насчет регулярных выражений: в данном примере я везде использовал XPath (кроме получения ссылок на изображения). Вместо XPath можно использовать регулярные выражения. Но проблема в том, что они разработаны для регулярных текстов, а html таковым не является. Это значит, что в общем случае вы не сможете получить произвольный кусок html.
Недостатки
Немного подытожу недостатки программы.
Очень запутанный интерфейс
Как любит говорить Умпутун, пользовательский интерфейс создан хищниками для чужих: разобраться в программе очень сложно.
Такое часто получается, если программисты сами придумывают дизайн приложения. С их точки зрения все сделано логично и удобно, но на самом деле проекту необходим толковый дизайнер интерфейсов.
И даже после того, как я разобрался что к чему, мне все равно пользоваться неудобно: приходится часто переключаться между многочисленными табами.
Получение данных методом POST
Datacol умеет получать странички только методом GET. На некоторых сайтах при отправке формы используется метод POST и в этом случае вы не сможете воспользоваться этой программой.
Что можно улучшить
Я не специалист в области интерфейсов, но все же попытаюсь дать несколько советов разработчикам.
- Дерево кампаний на главном экране программы – в топку. Кто работает сразу с несколькими кампаниями? Сделайте открытие и сохранение кампании, как документа Word или проекта Visual Studio. Все настройки парсинга должны происходить в главном окне.
- Табы – в топку. Я хочу видеть что за чем идет, а не переключаться между закладками. В идеале хотелось бы видеть что-то типа Yahoo Pipes.
- Установите на своем сайте Wiki и вносите в нее всю информацию по настройкам. На вопросы пользователей давайте ссылки на Wiki или отвечайте. Не посылайте их на три буквы!
Преимущества
Несмотря на мою критику, Datacol имеет немало преимуществ:
- Широкие возможности настройки
- Помощник составления строк вырезания (киллер фича приложения)
- Расширение функциональности с помощью плагинов
- Возможность автоматизации постинга данных на свой сайт
- Возможность получить решение своих задач за дополнительную плату
Заключение
Datacol пригодится вам, если вы готовы разбираться с настройкой программы и регулярными выражениями или не возражаете заплатить дополнительные деньги за настройку кампании.
